Voice Agent Evals - A Primer
The use of voice agents is growing. Every business, irrespective of size or industry, sees the value of leveraging voice agents to free up humans to do more strategic, value-adding work. The real challenge starts when you need to start tracking the return on investment.
I ran evaluation on a 30-turn conversation across 5 providers to dig deeper. If you're an AI researcher, PM working on scaling voice agents, or a founder exploring the voice agent landscape, this simplified framework will help.
Why is voice agent evaluation hard?
Voice agents operate across 2 modalities - voice and text - each with their own success criteria.
- Text evaluation: Did the voice agent say the right things?
- Instruction Following: Whether the assistant directly answered the question or advanced the workflow. Also catches word/action contradictions.
- Tool Use Correctness: Whether the assistant called the right function with semantically correct arguments at the right time.
- Knowledge Base Grounding: Whether all factual claims in the response are consistent with the knowledge base. Checks dates, times, room names, speaker names.
- No Hallucination: Whether every specific named entity the model mentions can be traced back to the KB or the conversation history. More targeted than KB Grounding — catches invented emails, fake session names, fabricated speaker names.
- Rule Following: Whether the assistant obeyed all stated operating constraints for this turn. The system prompt defines specific prohibitions; this metric checks they weren't violated.
- Response Naturalness: Whether the response sounds like something a human would naturally say in a live conversation, or whether it reads like a written document.
- Voice evaluation: Did the voice agent deliver it naturally?
- Turn Taking: Audio-level timing anomalies. Pre-computed from WAV analysis before text judging runs.
- Voice-to-Voice Latency: The pause a real caller experiences — time from when the user stops speaking to when the first spoken word from the bot is heard. This is the audible latency, not a server metric.
Learnings
I ran multiple evaluation simulations across voice and text. Here's what I learnt:
- Voice naturalness is the dominant failure mode: Despite specific instructions, models don't synthesize before giving responses. This behaviour is more pronounced when the knowledge base size increases.
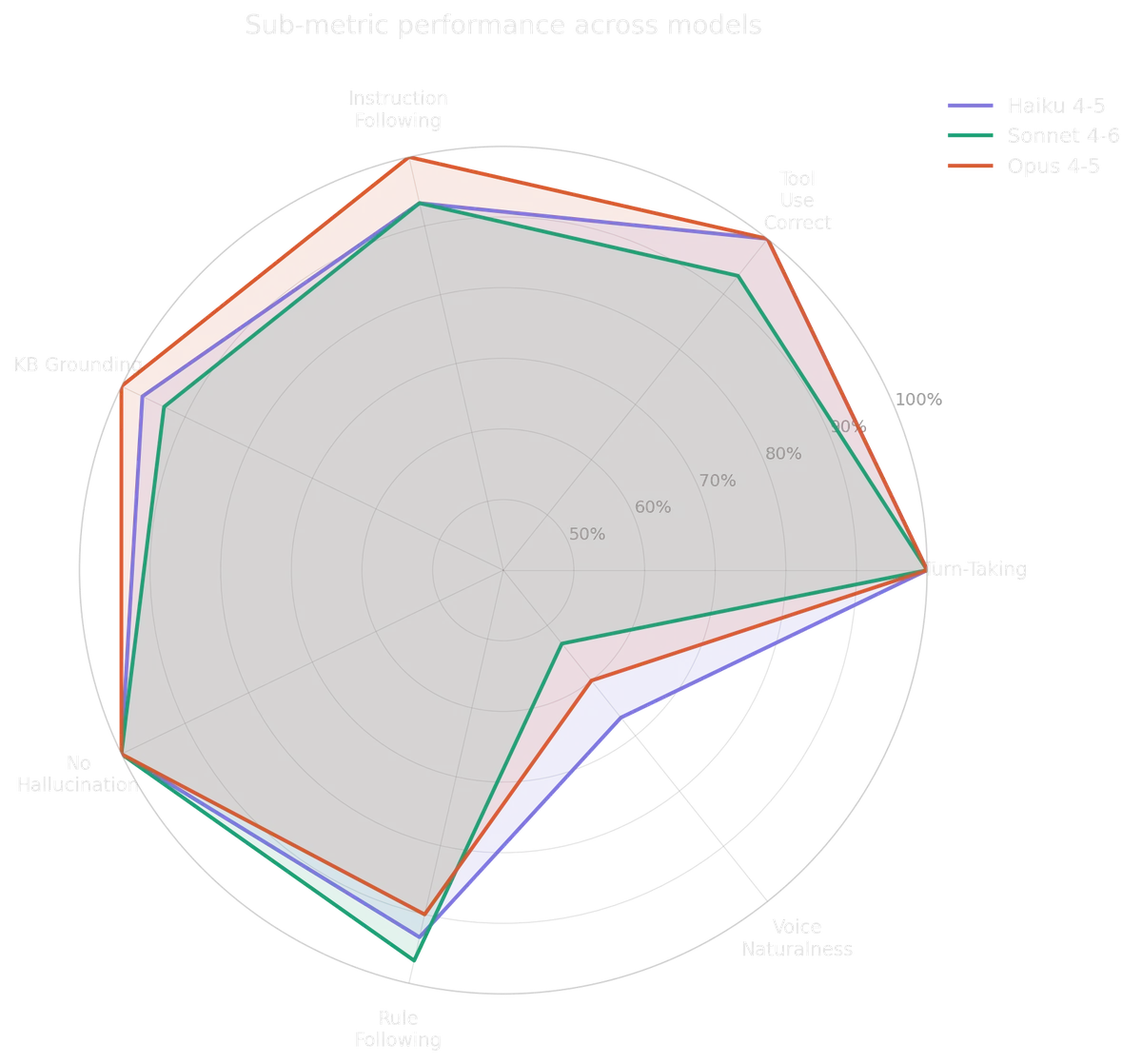
- Claude Sonnet tends to have cascading failures: A miss at one turn can translate to poor performance for next several turns.
- Grok Realtime consistently outperforms other speech-to-speech models: Tends to have the lowest standard deviation.
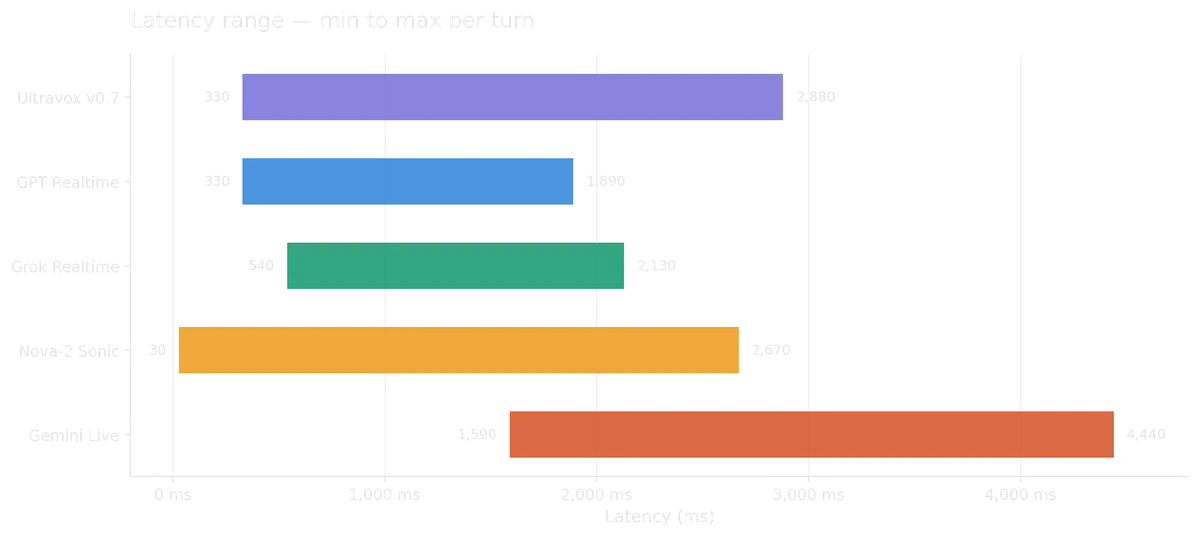
- Latency at higher turns is more important than median latency times: Ultravox v0.7 for example, had the best median response time, but response times spiked to 2-3 seconds when turns involved tool calling/reasoning.
- Defining a high quality golden dataset is positively correlated with evaluation success: Without it judging any aspect of the text modality is futile.
Next Steps
The evals space is evolving rapidly. This primer barely scratches the surface. As next steps here are a few areas I'm actively exploring.
- How do evaluation criteria scale across domains and use-cases?
- How does one reduce the friction to create a high quality golden data set?
- What strategies can be used for context management at higher # of turns?